資料4
今回の話は大体2つ:
- 最短距離を求めるアルゴリズムについて
- ダイクストラ法(必修)
- A*アルゴリズム(オプション)
- 優先度キュー
- ヒープソート等で利用されるヒープデータ構造
- 上記のアルゴリズムで利用
課題④へ
講義資料(1月11日更新) ← 授業後の訂正版
1 最短経路問題
1.1 問題設定
問題
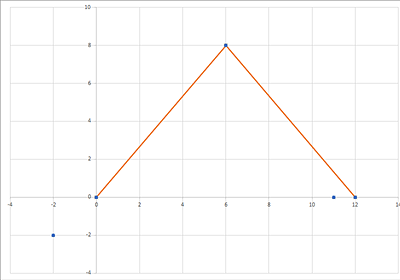
盤面に点が配置されています. 始点から終点まで移動したいのですが,2点間の距離が 10以下の場合だけ移動することができます. 以降で紹介する2種類のアルゴリズムを用いて,最短経路問題を解いてみましょう.
例えば、下記の図の例では、 始点 (0,0) から (6,8) を経由して (12,0) にたどり着くことができ,これが移動経路長を最小にする移動法になります.
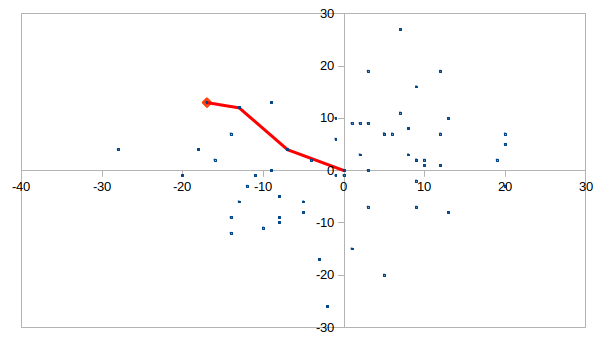
こう少し距離が長いケース:
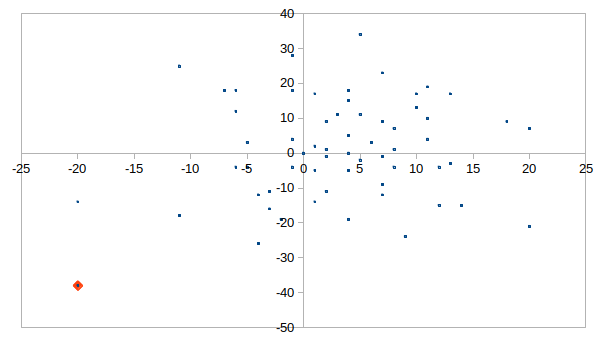
配置によっては,終点に到達できないケースも存在する:
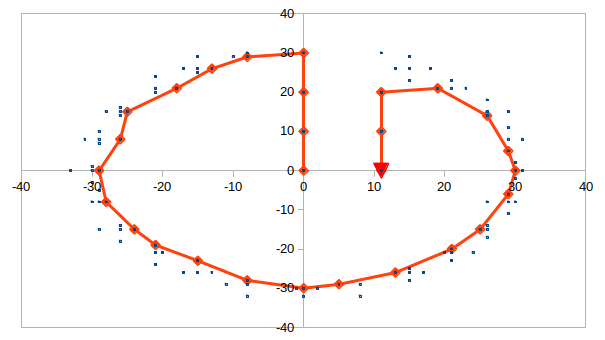
あるいは、意外と遠回ししなくてはいけないケースも存在する:
さて,これから2つのアルゴリズムを用いて,最短距離問題を解いてみましょう:
- 今日:ダイクストラ法(英語: Dijkstra’s Algorithm)
- 次回:A*(発音:A-Star)
1.2 ダイクストラ法
グラフの探索の場合,探索順序に注意しないと,何度も同じ場所をやり直す羽目になります. 計算量も膨大になってしまいます.
幅優先探索は,始点に近いノードから順番に探索をかけていくのですが,もし,枝(edge)に長さがある場合は,幅優先探索では「近い」ノードから探索したことにはなりません. ある点にいくのに複数の経路がある場合、後からしらべた経路の方が安上がりだったりするかもしれませんし、その場合、やり直しの可能性だって出てきます.
ダイクストラ法は、始点ノードから「近い」ノードから順番に、その到達コストを確定させていく方法です.
アルゴリズムの流れ
- 始点ノードへの経路長を 0, 他のノードへの経路長を無限大とする.
- 未探索ノードのうち経路長が最小のものを取り出す(
nとする).この時点でnへの経路長は確定できる.nの隣接ノードに対し,n経由で到達する経路長を求め,以前に求めた経路長より短くなる場合は更新する - 未探索ノードがなくなるまで,2 を繰り返す.
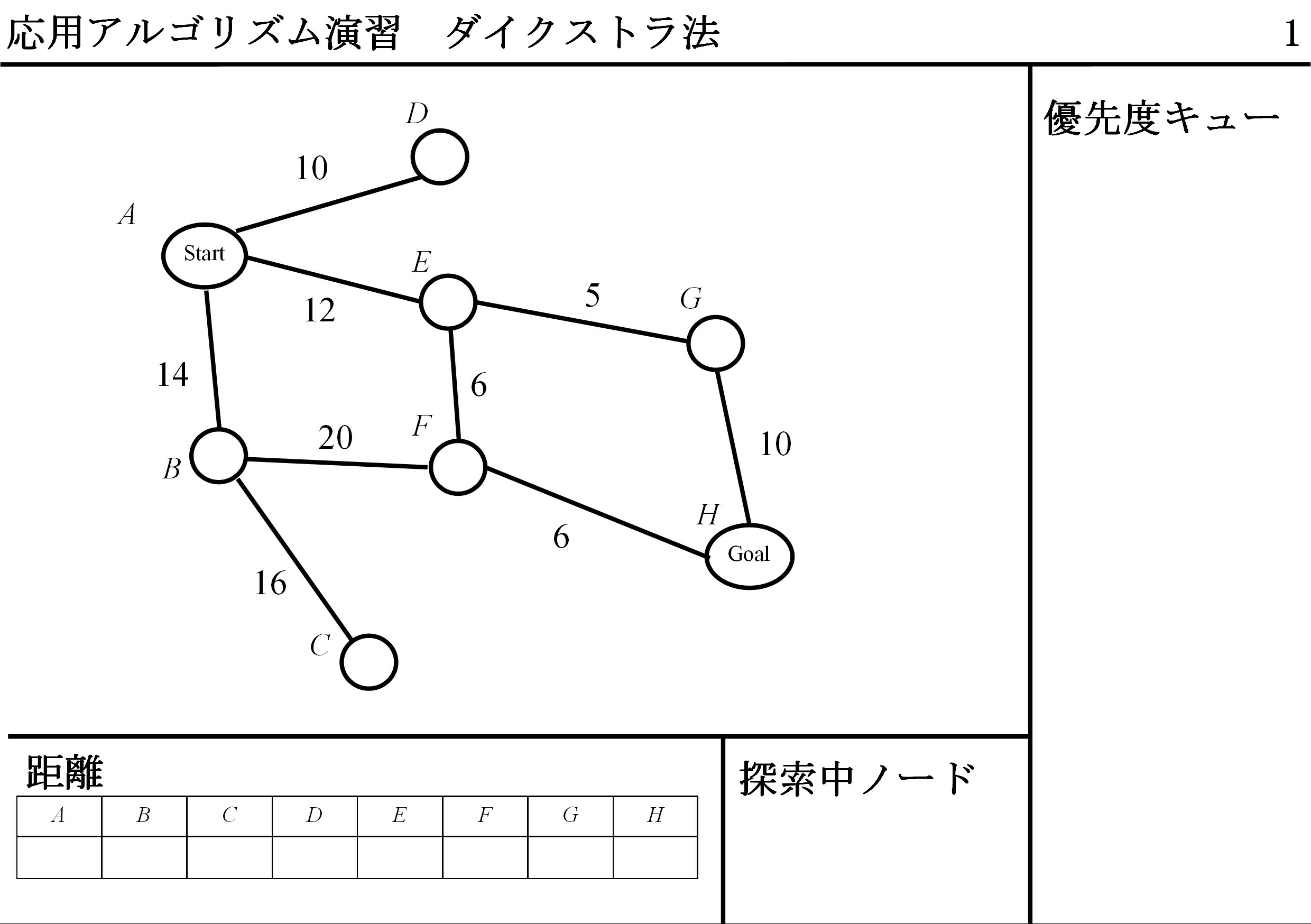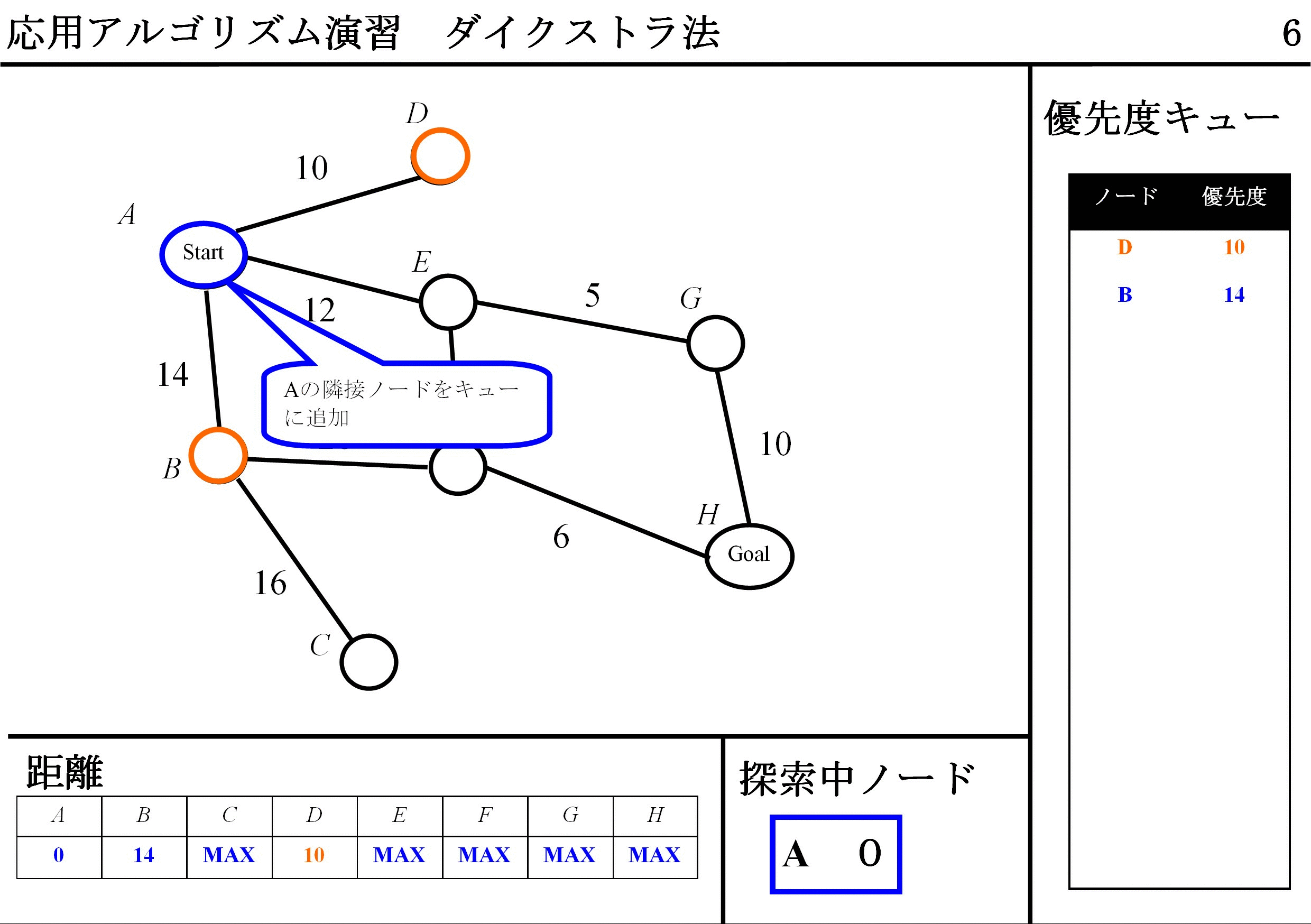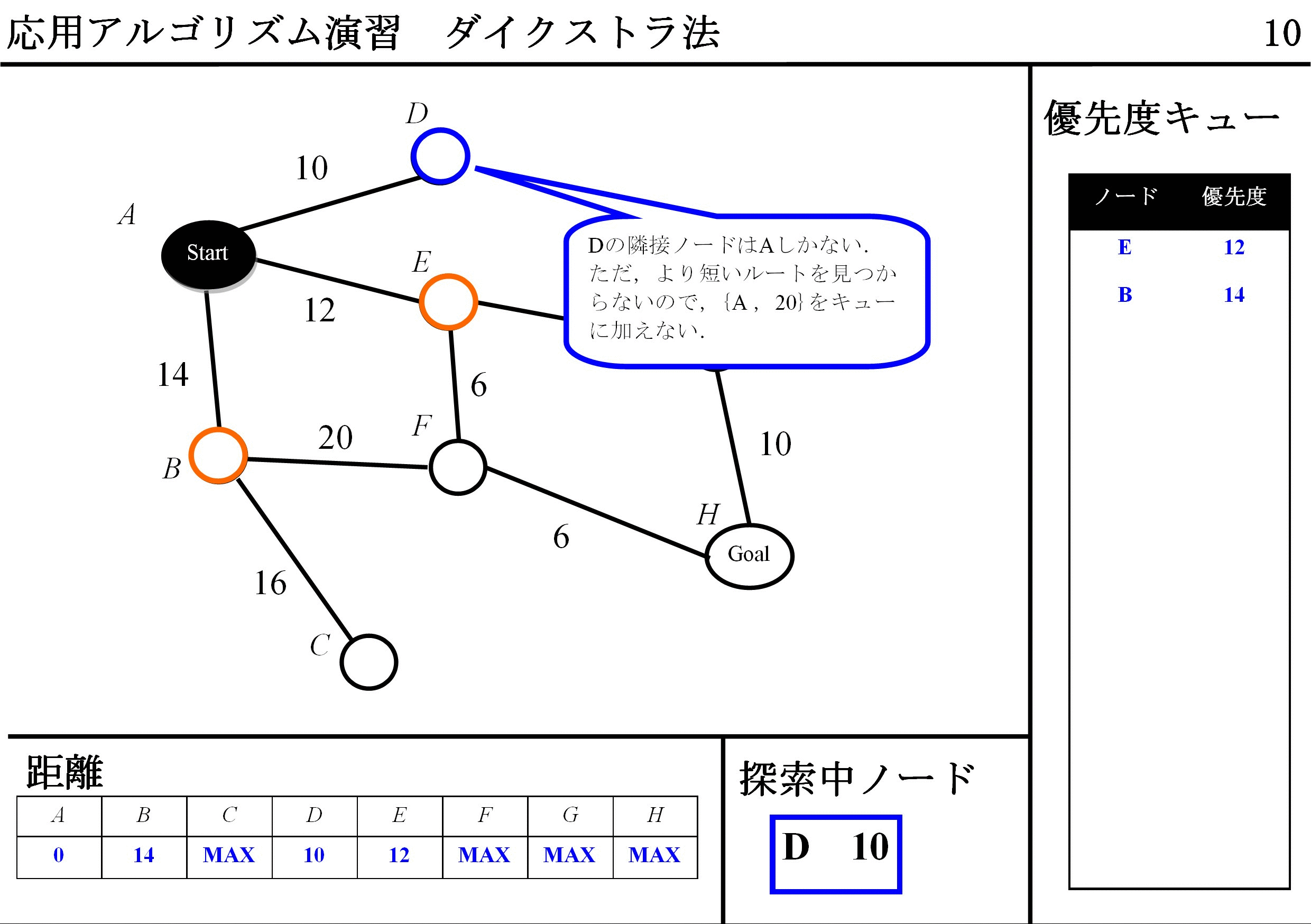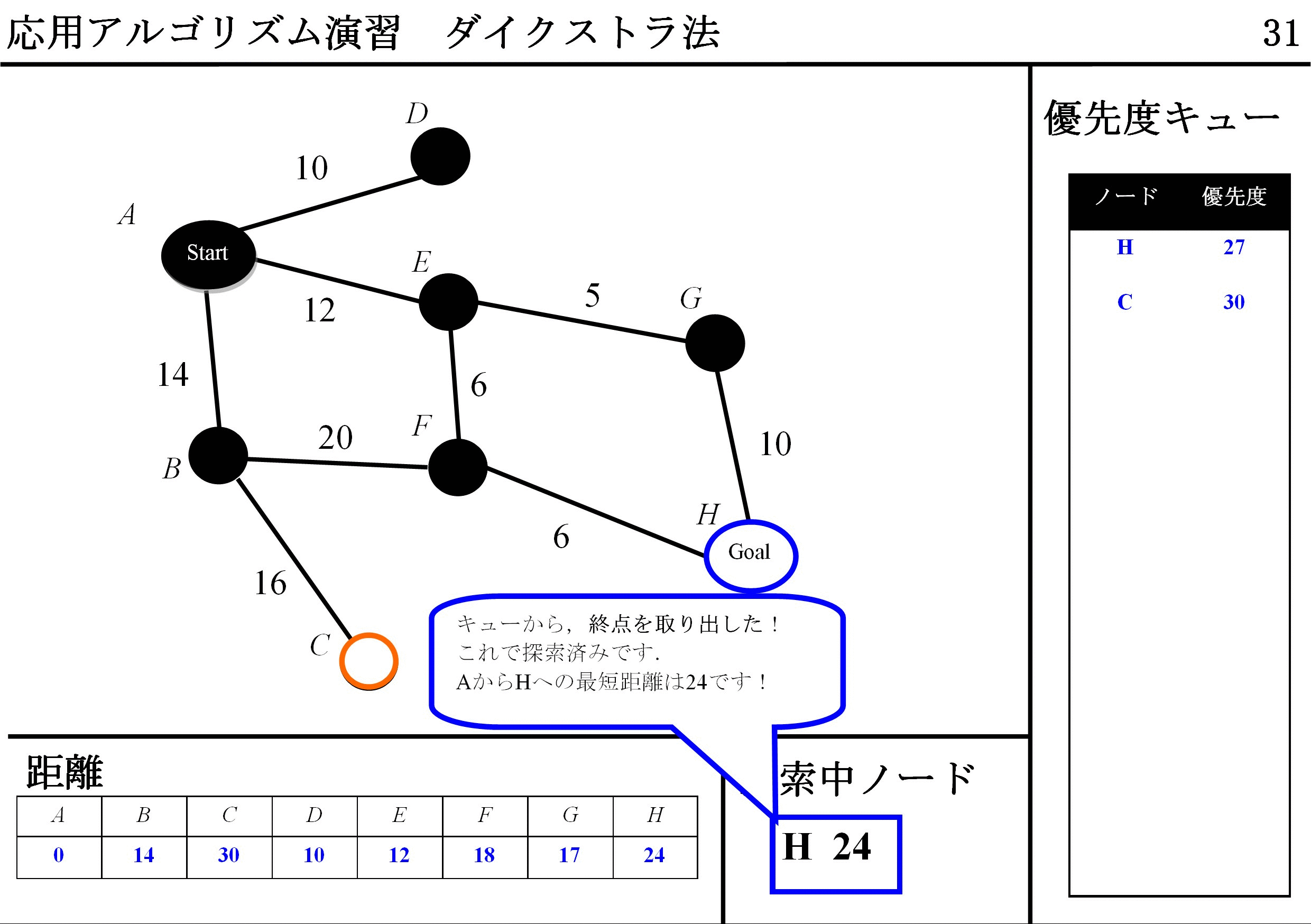
DFS(Depth-First Search / 幅優先探索)アルゴリズムとても近いですが,QueueはFIFOではなくて,優先度キュー使い,経路長最小のものから取り出すことができれば,アルゴリズムは完成です.
このプログラムでは,ゴールに到達した時点で計算を打ち切っていますが,最後までやれば,始点 からすべての点への最短経路も求まります.
注意: このアルゴリズムは、枝のコストに負の値が含まれる場合は機能しません. 一時的に「遠く」なっても、あとで「相殺」できるってことだと,「近いところから」確定できません. 別の言い方をすると,「(中間)解をみつけた」つもりでいても,後から「もっといい(中間)解」がみつかったら、やり直しになります.
1.3 プログラム実装
プログラムは shortestPath/dijkstra.cです.
前半は優先度キュー部分で,後半にダイクストラ法を実装した double solve(int n) 関数があります.
注: 今回のプログラムは sqrt() を利用しているので,コンパイル時に -lm optionを渡す必要があります.
VS code を使っている人は,tasks.jsonのコンパイルオプション設定部に -lm を追加してください.
こんな感じ:
{ ...
"tasks": [
{
"args": [
"-g",
"${file}",
"-lm",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],
...
}
]
}
今回、探索ノードとしてstruct searchNodeというデータ構造を準備しました.
typedef struct searchNode {
double pathLen; /* 対象ノードまでの経路長 */
int index; /* 対象ノード */
} searchNode_t;
- 入力された点の情報は,点の個数を
int nに,点データをpoints[]に格納しています. double cost[]は,始点から各点までの最短経路長を記憶しておくための配列です.好きにつかってください.double solve(int n)がプログラム本体です.- 始点から終点までたどり着ける場合は,その最短経路長を結果として返しましょう
- たどり着けない場合は、
0.0を返す.
2 A*アルゴリズム
2.1 ダイクストラ法の欠点
任意のグラフだと,ダイクストラ法は最短ルートを確実に見つかるのですが,時々無駄な探索も多いです. 例えば下記のグラフを検討して下さい.阪南から神戸までの距離を求めたいです.
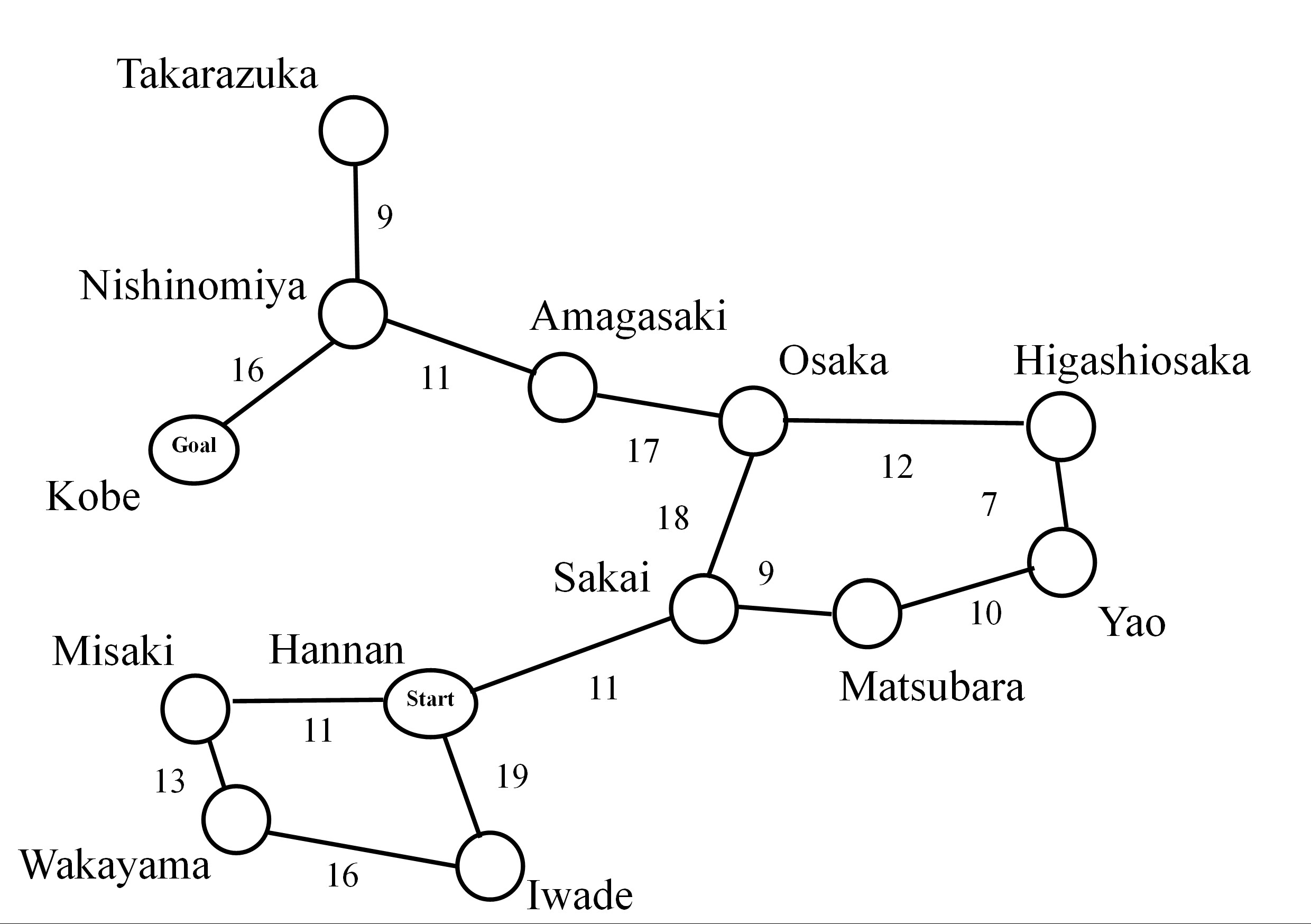
上の状況だと通常のダイクストラ法を利用した場合は,すべてのノードを探索することになります(自分で確認して下さい).
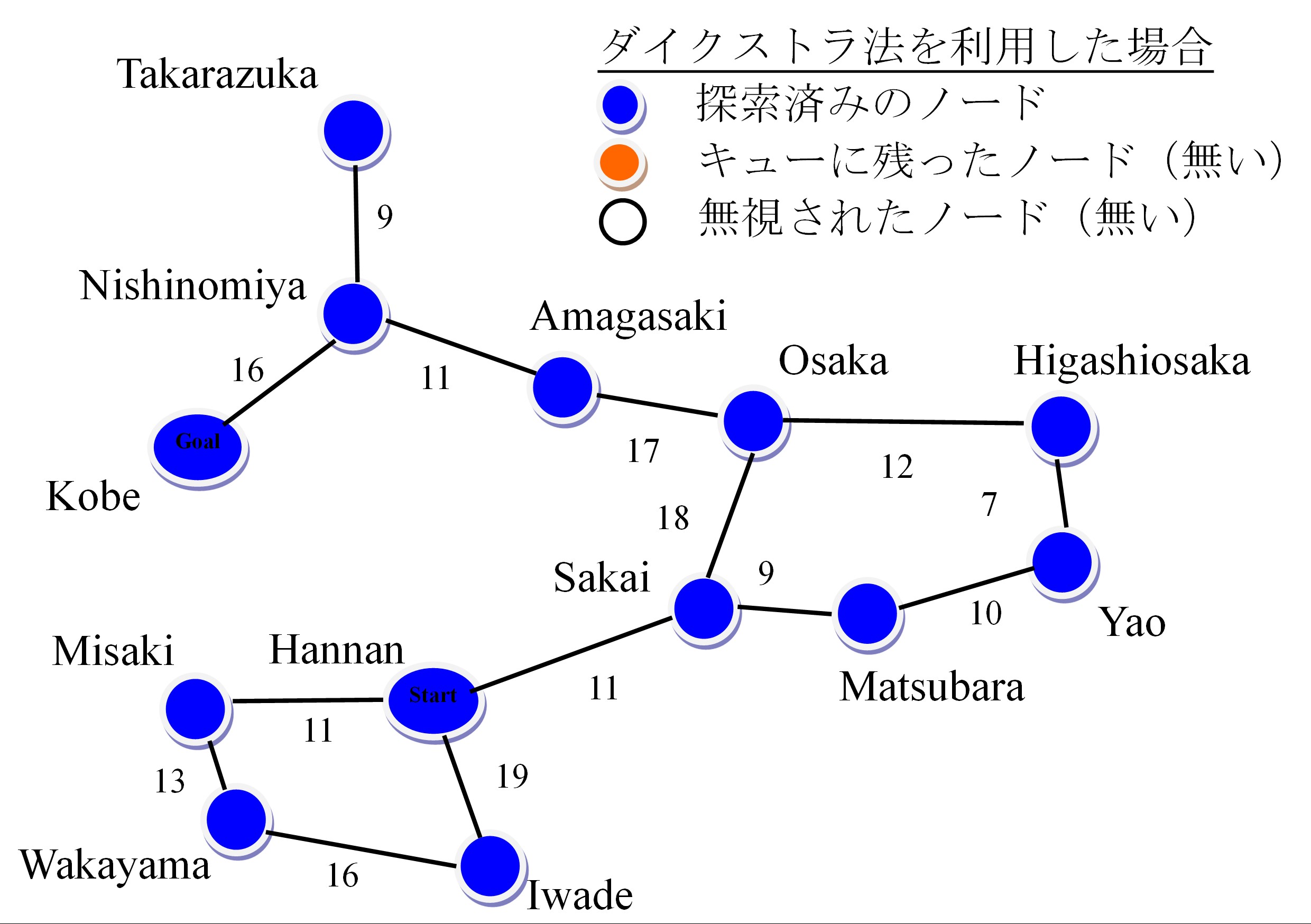
頂点を決まっているのに,ダイクストラ法では逆方向も探索するんです. 例えば神戸から東京への最短ルートを計算したかったら,ダイクストラ法は広島行きの道も(無駄に)探索する.
2.2 A*アルゴリズムの提案
上記の状況だと,ノードの(2次元の空間内の)配置とノード間の距離の相関関係が強いです. つまり,頂点から離れるほど,短いなルートを見つかる確率が低いです. 逆に,頂点に近づくほど,短いなルートを見つかる確率が高いです. A*アルゴリズムは,この施設を利用して,より効率的な最短ルートアルゴリズムです.
A*アルゴリズムの実装はダイクストラ法とほとんど同じです. 違うところはただ一つ:キューの優先度です. ダイクストラ法ではスタートのノードから当ノードまでかかった距離順で並べるんです. A*の場合は,当ノードまでかかった距離と,当ノードから頂点まだ掛かりそうな距離も考量するんです. 優先度は (今まで掛かった距離 + これから掛かりそうな距離) の合計になる. 結果,探索するノードは削減出来る.
今回,頂点までのまたかかりそうな距離を2次元空間のユークリッド距離で決定する(下記の図では +%% で表示している).
この新しい優先度の定義だと,和歌山や東大阪や宝塚も優先度キューに加えるんだが,探索されない.
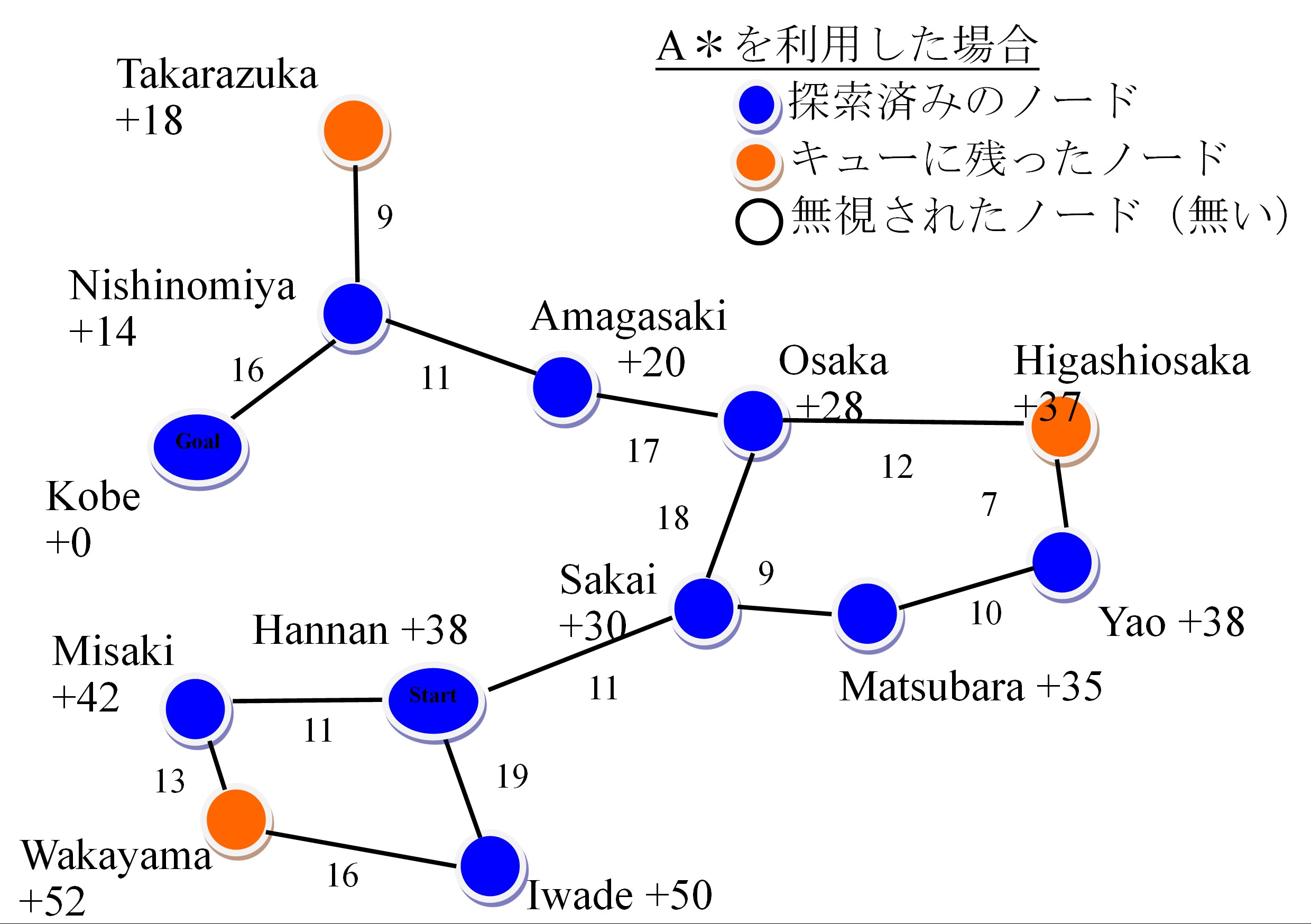
興味があれば,A*アルゴリズムを実行して,上記の図と同じ結果を得ることを確認して下さい.
ヒント:阪南探索済みの時点で,優先度キューに順番に酒井(優先度41),美咲(優先度53),岩出(優先度69)を記録されている.
そのあと,酒井を探索して,大阪(優先度57)と松原(優先度55)をキューに加える…
3 優先度キュー
先のダイクストラ法では,優先度キューを利用していました. その優先度キューの実装・使い方等色々学びましょう. shortestPath/priorityQtest.cを参考にして下さい.
3.1 基本データ構造
優先度キューは、Queue (待ち行列)の一種ですが、指定した優先度順に要素を取り出すことができるものです. 要素を全部詰めてからソートして順番に取り出す「わけではなく」、 随時、要素を加えたり、取り出したりすることができます。便利です.
とりあえず、優先度キューを使うだけのプログラム例を配置しましたので、利用イメージを理解しましょう。前半がライブラリ部で、後半の main() が利用部です.
このプログラムでソートしているのは、struct myitem というデータ構造です.
typedef struct myitem {
double priority; /* 優先度、低いほうが優先ってことにします */
int id; /* 要素識別用の番号 */
} myitem_t;
利用しているのは、とりあえずこの関数群.
ELEM dequeue(): 要素を取り出すvoid enqueue(ELEM a): 要素を加えるint compare(ELEM * a, ELEM * b)は、a,bの並び順(大小)を比較する関数です.利用者に定義してもらう.
以下が、利用コードです.
priorityQ_t Q;
int main(void)
{
int i;
myitem_t items[] = {
{100.0, 0}, /* priority, id */
{10.0, 1},
{20.0, 2},
{10.0, 3},
{100.0, 4},
{5.5, 5},
{3.0, 6},
{30.0, 7}};
for (i = 0; i < 4; i++)
{
enqueue(&Q, items[i]);
}
printQueueInside(&Q);
for (i = 4; i < 8; i++)
{
myitem_t r = dequeue(&Q);
printf("enqueue (2nd stage):");
printItem(&r);
printf("\r\n");
enqueue(&Q, items[i]);
}
while (qSize(&Q) > 0)
{
myitem_t r = dequeue(&Q);
printf("dequeue (3rd stage):");
printItem(&r);
printf("\r\n");
}
printf("finish!\r\n");
return 0;
}
実行結果は:
[priorityQ, size: 4, body:{[10.000000,1], [10.000000,3], [20.000000,2], [100.000000,0]}]
dequeue (2nd stage):[10.000000,1]
dequeue (2nd stage):[10.000000,3]
dequeue (2nd stage):[5.500000,5]
dequeue (2nd stage):[3.000000,6]
dequeue (3rd stage):[20.000000,2]
dequeue (3rd stage):[30.000000,7]
dequeue (3rd stage):[100.000000,0]
dequeue (3rd stage):[100.000000,4]
finish!
3.2 優先度キューの内部実装
内部実装は、ヒープソートで利用するヒープを利用しています.
基本木構造データ構造です。小さい順にソートしている場合、親は子供のいずれよりも小さいというルールが守られます.
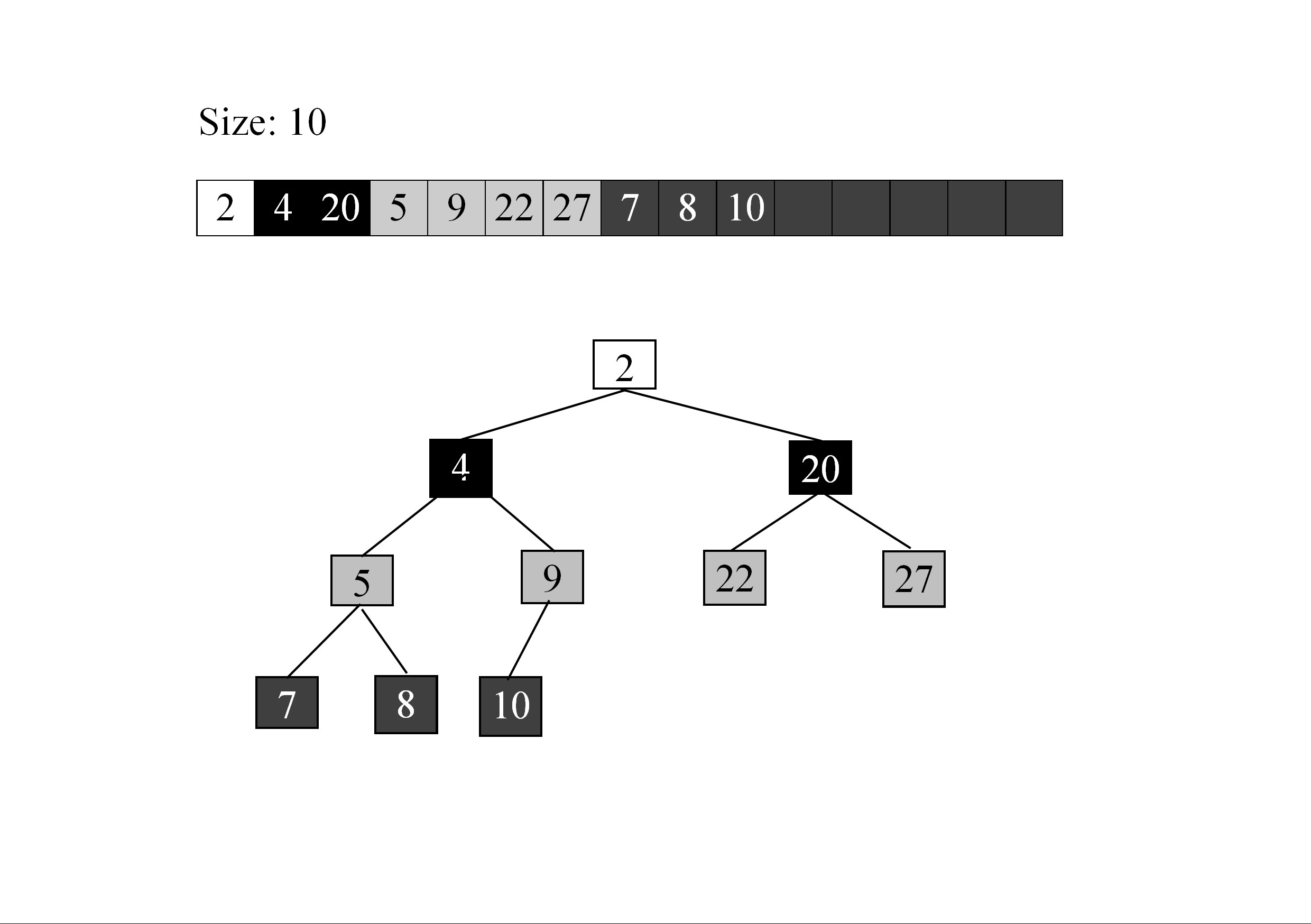
そのうえで、enqueue, dequeue に際して
- enqueue: 最後尾に要素を加える。そのうえで、以下の upheap をおこなう.
- 追加要素が、その親より小さい場合は、交換する.
- このような親との比較を、親が追加要素以下になるまで繰り返す.
- dequeue: 先頭要素を返す。そのうえで、最後尾要素を、先頭に移動させ、以下のdownheap をおこなう.
- 移動要素が、子供のいずれかより大きい場合、小さいほうの子供と入れ替える.
- このような親との比較を、子供が追加要素以上になるまで繰り返す.
プログラムは、shortestPath/priorityQtest.cの43-157行目あたりです. 興味がある人は読んでみてください.
なぜヒープソートで木構造のデータ構造を利用する?
理由は時間計算量です.例えば,同じ1次元の配列でそれぞれのを要素を順番にソートした場合は,新しい要素をEnqueueするときに,入れる場所を見つかると,その次の要素をずれるために, N 要素があれば,O(N) の時間計算量がかかる.
最初からHeap Sortで管理した場合は,O(log N) の時間計算量がかかる.
3.3 比較方法
優先度キューでは,比較用関数を利用者が定義する必要があります. というのも、提供しているライブラリは,汎用を目指しているので,要素型は,なにが来ても大丈夫にしたいのですが,だからこそ比較の仕方は前もって決めておけないわけです.
/*
* - *a, *b の比較結果を返す
* - *a, *b の順に並べるべき時は、負の数を返す
* - *b, *a の順に並べるべき時は、正の数を返す
* - 同じ大きさの場合は、0を返す
*/
int compare(ELEM *a, ELEM *b);
例: int を小さい順に並べる場合
int compare(int * a, int * b) {
if(*a < *b) return -1;
if(*a > *b) return 1;
return 0;
}
/* 桁あふれが無視できるなら、 下記の感じでも OK */
int compare (int *a, int * b) {
return *a-*b;
}
そのような比較方法は,C言語でも基準ライブラリとして適用されています:
/*
* - base: 配列の先頭アドレス
* - num: 要素数
* - size: 要素ひとつあたりのサイズ(byte数, sizeof)
* - compar: 比較用関数へのポインタ。まあ、関数名だと思っておいてください
*/
void qsort(void * base, size_t num, size_t size, int (*compar)(const void *, const void *));
利用例は,shortestPath/useQsort.cにある.
typedef struct point { /* 座標 */
int x, y;
} point_t, * point_tp;
/* 比較用関数。a, b アドレスにある座標データを比較する。
x 座標が小さいものが前で、x座標が同じ場合は、y座標で比較 */
int compare0(const void * a, const void * b) {
/* ポインタ型を、本来の point_tp に変換しよう */
point_tp ap = (point_tp)a;
point_tp bp = (point_tp)b;
int result = ap->x - bp->x;
if(result==0) return ap->y-bp->y;
return result;
}
int main(void) {
int i;
/* ポイントをソートしよう */
point_t ps[] = { {1,3}, {12,4}, {5,2}, {7, 8} };
/* qsort 呼出し */
qsort(&ps, 4, sizeof(point_t), compare0);
/* 表示してみる */
for(i=0; i<4; i++) {
printf("(%d %d), ", ps[i].x, ps[i].y);
}
printf("\n");
}