課題1
今回は、演習時間も短いし、プログラミングなしの課題となっています。
有向グラフを深さ優先探索してみましょう。 プログラムはこちらにあるので、プログラムの実行理解をしましょう。 ついでに、デバッガでプログラムがどのように動作しているか、しっかり追っかけられるようになりましょう。
まずは、データ構造。
id はノードの識別子であり, visited はノードの訪問回数を示す。
struct node はグラフのノードを表し、配列 neighbors がノードへの参照を値として持つことは、そのノードから参照先ノードへのエッジ(edge)が存在することを示している。
当ノードが持つエッジの数は neighborsCount で記録しております。neighbors の配列の中に、i < neighborsCount でしたら、neighbors[i] が意味があります。
#define BUFSIZE 100
#define MAX_NEIGHBORS 10
typedef struct node {
int id; /* ノード名*/
int visited; /* 探索された回数 */
int neighborCount; /* 隣接するノードの数、neighbors 配列の最大引数 */
struct node * neighbors[MAX_NEIGHBORS]; /* 隣接するノードの配列、ポインターとして記録 */
} node_t;
node_t nodes[BUFSIZE];
一方で、探索プログラムはこんな感じ。
再帰的に探索をおこなうが、1度たどったところは、2度以上探索しないようにしています。
エッジは、neighbors 配列の順で調べていきます。
/* 深さ優先探索 */
void dfs(node_t * node) {
printNode(node);
node->visited++;
if (node->visited == 1) { /* 当 node が初めて出た場合は… */
int n;
for (n = 0; n < node->neighborCount; n++) { /* …隣接するノードを再帰的に探索 */
node_t * next = node->neighbors[n];
dfs(next);
}
}
/* 初めてじゃ無かった時、あるいは隣接するノード全部探索済みになった時に、呼出側に戻る */
}
下記が、グラフを作成してから探索を行っている部分。
/* n ノードを初期化する */
void initNodes(int n) {
int i;
for(i = 0; i<n; i++) {
nodes[i].id = i;
nodes[i].visited = 0;
nodes[i].neighborCount = 0;
}
}
/* origin から destination へ枝を追加 */
void link(node_t * origin, node_t * destination) {
origin->neighbors[origin->neighborCount] = destination;
origin->neighborCount++;
}
void test1(void) {
/* グラフの定義 */
initNodes(4);
link(&nodes[0], &nodes[2]); /* 0 -> 2 */
link(&nodes[0], &nodes[1]); /* 0 -> 1 */
link(&nodes[1], &nodes[2]); /* 1 -> 2 */
link(&nodes[1], &nodes[3]); /* 1 -> 3 */
link(&nodes[2], &nodes[3]); /* 2 -> 3 */
link(&nodes[3], &nodes[0]); /* 3 -> 0 */
/* 深さ優先探索 */
dfs(&nodes[0]); /* ノード 0 からスタート */
}
例えば、test1() の場合、以下のようなグラフができているはず。
あるノードから枝が2つある場合は、s の枝が先に探索されます。
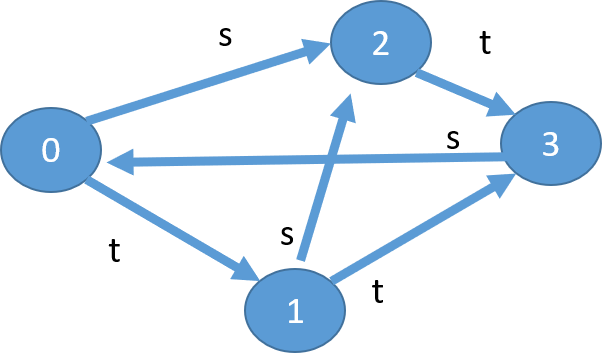
さて、以下が課題になります。
問題1
test1() を実行した際の実行結果を確認しましょう。
int main(void) {
test1();
return 0;
}
その上で、関数の Call Stack がどのように変化しながらプログラム実行が進んでいたか、コメント風に記述しなさい。 冒頭部だけ書くと、こんな感じ。
(node 0, visited 0 times) // stack:0
(node 2, visited 0 times) // stack:0:2
(node 3, visited 0 times) // ...
(node 0, visited 1 times) //
(node 1, visited 0 times) //
(node 2, visited 1 times) //
(node 3, visited 1 times) //
// stack:.. の部分は、頭で考えてもらっても良いし、デバッガでprintNodes()に break point をいれて、調べても良いし、以下の option 課題を解くことで実現しても良いです。
問題2
dfs 関数中の if 文を以下のように書き換えたとします。
void dfs(node_t * node) {
printNode(node);
node->visited++;
if (1) { /* 変更点! 常に then 節を実行 */
int n;
for (n = 0; n < node->neighborCount; n++) {
node_t * next = node->neighbors[n];
dfs(next);
}
}
}
つまり、同じノードを何度でも探索しなおすこととします。
- 質問1 このとき test2 を実行した際の
nodes[10]の訪問回数は、どうなるでしょう?nodes[12]の訪問回数?nodes[5]の訪問回数は? - 質問2 このとき test2 を実行した時、なぜ無限ループになりませんでしたか?
void test2(void) {
int i;
initNodes(13); /* ノード 0 を使わない、ノード 1~12 を準備 */
for(i=3; i<13; i++) {
link(&nodes[i], &nodes[i-1]); /* i -> i-1 */
link(&nodes[i], &nodes[i-2]); /* i -> i-2 */
}
/* 深さ優先探索 */
dfs(&nodes[10]); /* ノード 10 からスタート */
}
真面目に手でやると大変なんですが、実は、nodes[10] の訪問回数は fib(10) に一致します。
理由を考え、簡単に答えましょう。
ちなみに、fib(n) はフィボナッチ関数のことで、
int fib(int n) {
if(n==0 || n==1) {
return 1;
}
return fib(n-1)+fib(n-2);
}
で求まる関数とします。
問題3(オプション課題)
上記の問題1の深さ優先探索は再帰関数で実装されました。 自作のスタックを(ある程度汎用的に)作って、再帰でない実装に変化してみて下さい。
オプション課題なので、全員がとかなくても大丈夫です。ただ、次の課題にいい練習になります。 スタックの実装だけを提出、アルゴリズムの実装も提出しても構いません。 上手く行けなくても評価するので、是非やってみて、出来たものを提出してください。
提出に求めるのが:
- ソースコード
- レポート(データ構造の説明、再帰実装の違うところ、最大半ページ程度)
課題提出
レポートを PDF で作成し、Beef+ から提出してください。
オプション課題を解いた人は、プログラムも提出すること。 提出締め切りは、10/19(木) 12:00
再提出
問題1の再提出を認めます.
この資料をご覧になって 更新したkadai1.c の test3() で作成されているグラフでもう一度取り組んでみて下さい.
提出はBeef+の課題1=再提出=,締め切りは11/24(金)